Frequently Asked Questions

Get clarification or answers for the most common questions we receive about Streamdal. Can’t find what you’re looking for, or need more details? Get in touch with us.
-
Streamdal is an open source observability tool.
It’s comprised of a server, a UI, and a bunch of Wasm-powered SDKs. By using our SDK and deploying it’s server, you’ll get a dynamic graph of your producers and consumers as they scale up and down, with the ability to tap in and view all the real-time data flowing through them with Tail.
You can use Tail from the Console UI. Or, for those who prefer a terminal, you can use the CLI.
The stuff you can use to modify your “in-flight” data such as stripping PII, masking, obfuscating, or validating data is of a certain format or structure, etc is done with rules. Currently, rules and the preventive/data governance features are in beta.
-
- Import our SDK for your language.
- Weave the
Process()method into the fabric of your code where data production or consumption takes place. - Deploy the Streamdal server where the services using the Streamdal SDK are running.
Check out the quickstart guide.
You can find more details in our guides on instrumentation and deployment.
-
Any source, and any destination.
The way Streamdal is instrumented, there isn’t a need for connectors or interfacing with various API’s. The SDK uses a
Process()method that is wrapped around the parts of your code where data production and consumption take place. -
The work all happens locally in the SDK, and on the client. The server component is just there to configure things on the client by shipping down rules created in the Console UI.
This happens with only a negligible resource hit to the client (usally <0.1ms, thanks to Wasm). There is no sending data, or shipping logs, metrics, or traces anywhere.
Check out our benchmark tests on GitHub.
-
There are many reasons why your service isn’t showing up on the data graph - from misconfiguration, to network issues, to improper SDK usage.
Here are some troubleshooting tips:
- The SDK should be imported and properly instrumented for your language. See the Golang example on importing the SDK.
- The server needs to be accessible by the SDK.
If you have confirmed the containers are up, try running
curl <streamdal-server>:<endpoints>. Check out the various endpoints exposed by the server components for further testing.- The
STREAMDAL_URLdefault environment variable value islocalhost:9090. If you are running the server somewhere other than where your instrumented services live, you will need to update this value to the correct address.
- The
- Make sure to see if the initial instantiation is producing an error. For example,
in the Golang SDK, the
streamdal.New(...)method returns the client and error - check if error is non-nil. - The
Process()method MUST fire at least once in order for the service to show up on the data graph. This is extremely common: a service might be callingRegister()but never reaches aProcess()call. - Make sure that the instantiated Streamdal client stays available for the entire
runtime of your service. The Streamdal client launches several background workers
that are responsible for receiving commands from the server, sending heartbeats,
metrics and many other things. If the Streamdal client is closed, the even if the
Process()call completes, the service will not show as “attached” on the data graph.- Common practice is to instantiate the Streamdal client at startup and make it available to other parts of the your application for continuous re-use.
- In most cases, the ony time the Streamdal client should get closed/destroyed is when your service is shutting down.
- Try to clear the Redis store that Streamdal server uses via
redis-cli: clear allstreamdal_*keys or perform aFLUSHALLcommand; followed by a re-start of Streamdal server. The server will repopulate the Redis store with the correct data. - Make sure your service stays running and does not prematurely exit. If the streamdal client is closed (due to your service exiting) - the service will never show as “attached” on the data graph.
-
Rules are currently in beta along with the other data governance features of Streamdal.
They are being tested by a select group of contributors, companies, and design partners.
These features aren’t production-ready! But, if you would like to get test access or become a design partner, contact us or hit us up on discord.
-
The observability aspects and features of Streamdal, including Tail, will always be free and open source using the Apache License v2.0.
Currently, the data governance features are in beta, but once they are fully fleshed out and production-ready, they may be a paid feature. We haven’t decided which parts of the governance features might need to be paid.
Regardless of how that decision pans out, we will not be rug-pulling anything we put out as open source.
Check out our launch manifesto for details on this design decision.
-
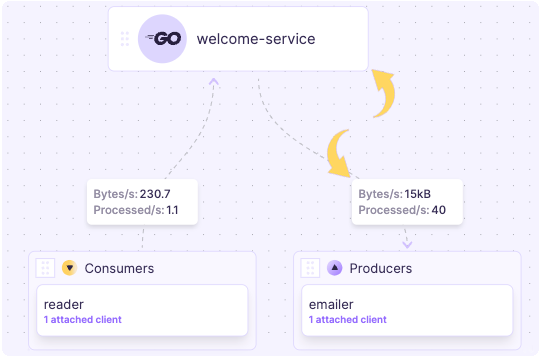
The Data Graph is real-time and dynamic.
What that means is so long as the server component is running, and new services are instrumented with the SDK, the Data Graph will not require maintenance.
The view you get will always be an accurate representation of data flowing through your systems regardless of scale.
-
Currently, there is no need to manage schemas. Once you have instrumented the SDK, you will be able to view the active schemas of data throughout your systems.
When you weave the
Process()method throughout your code, behind the scenes the SDK will infer and decode schemas, and present them in a human-readable format via the Console UI.We have big plans to expand schemas in the future. This could include tools, management capabilities, or functionality such as history and diff views.
Reference the roadmap for more information.
-
Tail gets its name from the Unix command and argument
tail -f.It is a feature that can be used via the Console UI (or CLI) which will allow you to tap into any of your producers or consumers and view the real-time data flowing through them.
Because schemas are inferred and decoded, you’ll be able to observe your data in a human-readable format.
-
Observability can be a really loaded term, which is why we also define it in our glossary and have a whole section dedicated to it. Depending on what you’re working with or who you’re speaking to, it can mean many different things.
When we say observability, we mean:
The ability to simply see the actual real-time data, its schema, and the services generating data or interacting with it.
DORA (DevOps Research and Assessment) also has a good definition on observability within this context, which defines it as:
…tooling or a technical solution that allows teams to actively debug their system. Observability is based on exploring properties and patterns not defined in advance.
We see Tail as a crucial part of this, and the primary function enabling data observability with Streamdal. Here are the following features we consider as “observability” features:
👆That list is subject to additions over time, and not subtractions. Check out our manifesto for more information on this design choice.
-
Wasm is WebAssembly.
-
We make significant use of Wasm.
Rules are supported by Wasm 100%. Schema inference, rules, and any sort of business logic is going to be executed by Wasm in the SDK.
The reason we’re able to have such a low impact on any given client’s resources, usually less than 0.1ms, is because it’s being executed via Wasm. It’s open source.
Get more information on how we use it in the Wasm section of the monorepo, or read about this design choice in our manifesto.
-
Streamdal is open-source using the Apache License v2.0.
Review our contributing guidelines for more information.
-
We are unabashed fans of and experts with Protobuf. It’s used in the primary API - we use it everywhere. We have even released previous open source tools like plumber which has extensive protobuf support.
Right now Streamdal will only work with JSON or non-binary data, but we have plans to add support in the near future.
Check out our roadmap for updates.
-
Nearly everything.
The app is always connected to the backend and the server. It will receive and react to every update that happens on the server:
- Throughput information
- the Data Graph (i.e. when a new SDK is instrumented and the
Process()is called, it will start showing up on the data graph) - Tail
- Schemas
-
We refer to these as the audience, which identifies a specific service + operation type (consume or producer), and name for the operation type and component.
You will always see these. There is an envar for some of them, but these are declared via SDK instrumentation is instrumented.
Or in other words, when you call
streamdal.Process(...), you will pass the audience you’d like to identify that operation as. -
"Attached"indicates whether an SDK is actively connected to the server. If it is “attached”, you will be able to perform “Tail” on that particular node to observe the data that is flowing through it.In addition, a node with
1or more attached clients will also display the current throughput details in the data graph - this can be really useful for monitoring and debugging your service in real-time.If it is showing “0 attached”, it means the SDK is not actively connected to the server. If this is incorrect, refer to the troubleshooting steps lined out in the FAQ.