Streamdal Pipelines

Between the service and the destination on the Data Graph, you will see your producers and consumers (also known as readers or writers; what you assigned as an operation type when configuring the SDK). These are what you will be attaching pipelines to.
What are Pipelines?
Pipelines in Streamdal work similarly to pipelines in other products that utilize step-based workflows. They are logical checks and rules data must adhere to so it can continue to be processed by your applications, and subsequently sent “downstream” (i.e. written to a database, or passed to another application or service).
Pipelines are put together in the form of steps (which we refer to interchangeably as rules), and each step has a type which determine the kinds of actions to take on data.

You can also edit or create new pipelines by selecting an operation type (a producer or a consumer), and clicking on Create New Pipeline or Edit Pipeline (circled on the right menu above.)
On the high-level overview for how Streamdal all works together with it’s necessary components, pipelines are the “transformation rules” that are sent to the server, which are then converted to Wasm modules that are pushed to the SDK.
Step Types
| Step Types | Usage |
|---|---|
| Detective | Used to analyze a payload |
| Transform | Used to transform or extract data |
| Key/Value | Operations against built-in distributed K/V store |
| Schema Validation | Allows you to upload and version schemas to validate data against |
| HTTP Request | Used for CRUD operations and multiplexing data via HTTP |
Detective
Detective is used for performing various types of data analysis on JSON
payloads, including but not limited to:
- PII Detection
- Data Validation
- Key/Value Matching
- Existence Validation
- Data Format Checks
This step type accepts an
optional path to specifically search for, and when left empty detective will
search the entire payload.
Detective Types
| Personally Identifiable Information (PII) | Data Validation | String Matching | Data Formats |
|---|---|---|---|
| PII_ANY | IS_EMPTY | STRING_CONTAINS_ANY | TIMESTAMP_RFC3339 |
| PII_CREDIT_CARD | HAS_FIELD | STRING_CONTAINS_ALL | TIMESTAMP_UNIX_NANO |
| PII_SSN | IS_TYPE | REGEX | TIMESTAMP_UNIX |
| PII_E-MAIL | STRING_LENGTH_MIN | BOOLEAN_TRUE | |
| PII_PHONE | STRING_LENGTH_MAX | BOOLEAN_FALSE | |
| PII_DRIVER_LICENSE | STRING_LENGTH_RANGE | UUID | |
| PII_PASSPORT_ID | STRING_EQUAL | IPV4_ADDRESS | |
| PII_VIN_NUMBER | NUMERIC_EQUAL_TO | IPV6_ADDRESS | |
| PII_SERIAL_NUMBER | NUMERIC_GREATER_THAN | MAC_ADDRESS | |
| PII_LOGIN | NUMERIC_GREATER_EQUAL | URL | |
| PII_TAXPAYER_ID | NUMERIC_LESS_THAN | HOSTNAME | |
| PII_ADDRESS | NUMERIC_LESS_EQUAL | ||
| PII_SIGNATURE | NUMERIC_RANGE | ||
| PII_GEOLOCATION | NUMERIC_MIN | ||
| PII_EDUCATION | NUMERIC_MAX | ||
| PII_FINANCIAL | SEMVER | ||
| PII_HEALTH |
PII_KEYWORD
The PII_KEYWORD detective type will attempt to find sensitive info in JSON
payloads by analyzing field names and their relative location in the payload.
By default, this detective type will run in Performance mode - this mode
normalizes field names and compares them against a PII keyword hashmap.
The result is that “Performance” is extremely fast and incurs a very small
overhead penalty (<0.08ms per PII scan on a 10KB payload).
The downside of “Performance” mode is that it relies on exact key and path-based
lookups. Meaning, that if your payloads have fields like foo_AWS_SECRET_KEY_bar,
“Performance” will not pick up on it.
To address this, you can enable PII_KEYWORD to use Accuracy mode.
In this mode, Detective will perform hashmap based lookups, path comparison and
lastly perform a “keyword-in-string” check. While this incurs a higher resource
penalty cost (~1.5ms per PII scan on a 10KB payload), it results in significantly
more accurate PII detection.
NOTE: If you are concerned about the extra overhead that “Accuracy” mode will incur, configure the Streamdal SDK to use
async mode and enable sampling.

Pro tip: There are two “catch-all” PII scanners: PII_KEYWORD and PII_ANY
PII_KEYWORD is used for scanning for PII in KEYS.
PII_ANY is used for scanning for PII in VALUES.
Transform
Transform is used to make changes to data.
Transform Types
REPLACE_VALUE
This transform type will replace the values in the object fields.
Path is required.
Value is required.
DELETE_FIELD
This transform type will delete the object fields.
Path is required.
OBFUSCATE_VALUE
This transform type will obfuscate the object fields.
Path is required.
MASK_VALUE
This transform type will mask the the object fields.
Path is required.
TRUNCATE_VALUE
This transform type will truncate the object fields. Truncate length is determined by length or percentage
Path is required.
Value is required.
EXTRACT_VALUE
This transform type will extract the the object fields.
Path is required.
Extract will take only the selected paths, and drop all others. This type also allows you to flatten the resulting object.
Example:
{
"customer": {
"address": {
"street": "123 main st",
"city": "portland"
},
"client": {
"first_name": "John",
"last_name": "Doe"
}
}
}If you extract customer.client.first_name and customer.address.city, and
select the flatten option, the resulting JSON will look like:
{
"city": "portland",
"first_name": "John"
}Key/Value
All Streamdal clients come pre-built with a “local, distributed key/value store”.
“Local, distributed” is a strange term - here is what we mean:
- Every Streamdal client that uses the same Streamdal cluster has a copy of the full key/value store that is accessible to every other Streamdal client.
- The key/value store is stored entirely in memory.
- Pipeline steps can modify the contents of the key/value store and these changes will be propagated to all other Streamdal clients.
- Key/value does not incur ANY network hop penalty as it is stored entirely locally, in memory.
This feature enables users to build complex pipelines that involve looking up dynamic data, such as “known user id’s”, to implement idempotency or implementing a dedupe strategy.
Schema Validation
Schema validation is self-explanatory. This type is used to validate schemas. Schemas are accepted via pasting from the clipboard. We currently accept JSON schemas, but will accept protobuf and other binary schemas in the future.
Schema is required.
HTTP Request
The HTTP Request step allows you to perform an outbound HTTP request if a condition is met.
This step allows you to set a “Body Mode” to either Static or Use Previous Step Result.
When using Static, the body will be sent as specified. When using Use Previous Step Result -
the SDKs will construct a body that will look something like this:
{
"detective_result": {
"matches": [
{
"type": "DETECTIVE_TYPE_PII_KEYWORD",
"path": "email",
"value": null,
"pii_type": "Person"
},
{
"type": "DETECTIVE_TYPE_PII_KEYWORD",
"path": "password",
"value": null,
"pii_type": "Credentials"
},
{
"type": "DETECTIVE_TYPE_PII_KEYWORD",
"path": "birthdate",
"value": null,
"pii_type": "Person"
},
{
"type": "DETECTIVE_TYPE_PII_KEYWORD",
"path": "country",
"value": null,
"pii_type": "Address"
}
]
},
"audience": {
"service_name": "signup-service",
"component_name": "postgresql",
"operation_type": "OPERATION_TYPE_PRODUCER",
"operation_name": "verifier"
}
}NOTE: As of 05.2024, the only step type that can be used with Use Previous Step Results is Detective.
| Allowed HTTP Methods |
|---|
| GET |
| POST |
| PUT |
| DELETE |
| PATCH |
| HEAD |
| OPTIONS |
URL is required.
Request Body is required IF PII_KEYWORD mode is “Static”.
You are also able to pass key/value pairs that will be sent along as HTTP request headers.
Headers are optional (but you’ll probably want to include these in production environments).
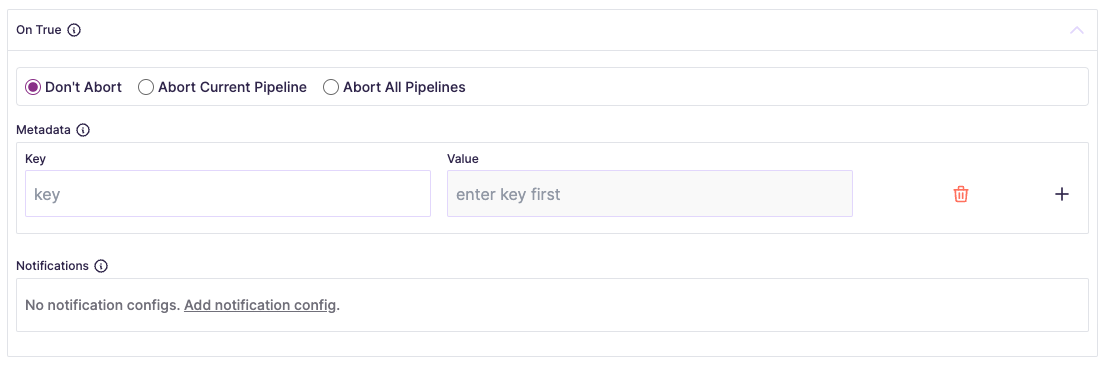
Pipeline Flow control
As pipelines execute, the resulting flow is determined via boolean or
ERROR results. When configuring pipelines, you can tailor each step to
control the execution of pipelines or optimize the flow of data at every step:

You can define how each pipeline should proceed by Don't Abort,
Abort Current Pipeline, Abort All Pipelines, adding Metadata (which
could be arbitrary keys and values that will be emitted to the calling code;
i.e. to enrich, categorize, or label data for downstream usage), or sending
Notifications:
Pro tip: Don’t forget to save pipelines after creating them!
Example Pipeline
There are many workflows you might normally configure in a traditional data pipeline. You might want to:
- Ensure no PII or sensitive data is in logs
- Route data
- Clean and reshape data
- Verify data consistency
- Handle errors
- Add automation
- Scale services or data platform
Below is an example of how you would set up a similar workflow as a Streamdal pipeline in the Console UI. In this example, you’ll see how you could use pipelines to truncate developer logs: